In this project, I attempt to create an application to predict the success of a video game based on its features. I will use data processing, feature engineering, machine learning, and visualization techniques to analyze the data and build a predictive model.
The raw data is a dataset of Steam games sourced from Kaggle.com. It includes various attributes such as game titles, platforms supported (Windows, Mac, Linux), features (Single-player, Multiplayer, etc.), and genres (Action, Adventure, etc.). The data also includes review scores and review counts.
Dataset
The project consists of the following steps:
<class 'pandas.core.frame.DataFrame'> RangeIndex: 42497 entries, 0 to 42496 Data columns (total 24 columns): # Column Non-Null Count Dtype --- ------ -------------- ----- 0 app_id 42497 non-null int64 1 title 42497 non-null object 2 release_date 42440 non-null object 3 genres 42410 non-null object 4 categories 42452 non-null object 5 developer 42307 non-null object 6 publisher 42286 non-null object 7 original_price 4859 non-null object 8 discount_percentage 4859 non-null object 9 discounted_price 42257 non-null object 10 dlc_available 42497 non-null int64 11 age_rating 42497 non-null int64 12 content_descriptor 2375 non-null object 13 about_description 42359 non-null object 14 win_support 42497 non-null bool 15 mac_support 42497 non-null bool 16 linux_support 42497 non-null bool 17 awards 42497 non-null int64 18 overall_review 40020 non-null object 19 overall_review_% 40020 non-null float64 20 overall_review_count 40020 non-null float64 21 recent_review 5503 non-null object 22 recent_review_% 5503 non-null float64 23 recent_review_count 5503 non-null float64 dtypes: bool(3), float64(4), int64(4), object(13) memory usage: 6.9+ MB
The initial dataset consists of 42,497 entries with 24 columns, including some with missing values and irrelevant information. After cleaning the data by removing duplicates and irrelevant columns and handling missing values, the dataset is reduced to a more manageable and relevant set of features.
<class 'pandas.core.frame.DataFrame'> RangeIndex: 42497 entries, 0 to 42496 Data columns (total 9 columns): # Column Non-Null Count Dtype --- ------ -------------- ----- 0 title 42497 non-null object 1 genres 42410 non-null object 2 categories 42452 non-null object 3 win_support 42497 non-null bool 4 mac_support 42497 non-null bool 5 linux_support 42497 non-null bool 6 overall_review 40020 non-null object 7 overall_review_% 40020 non-null float64 8 overall_review_count 40020 non-null float64 dtypes: bool(3), float64(2), object(4) memory usage: 2.1+ MB
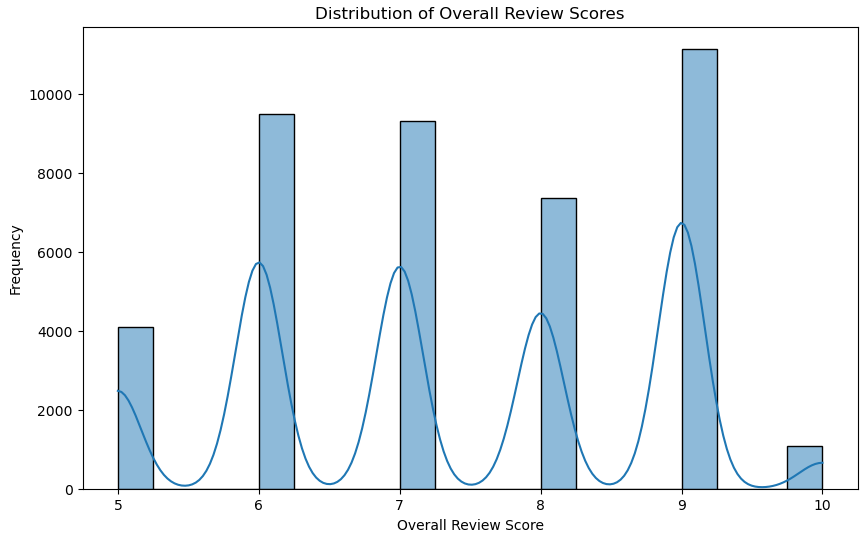
To better understand the data, I explore the relationships between various features and their impact on the target variable. Using visualizations such as histograms, scatter plots, and correlation matrices, I identify patterns and trends that would be important for building the model.
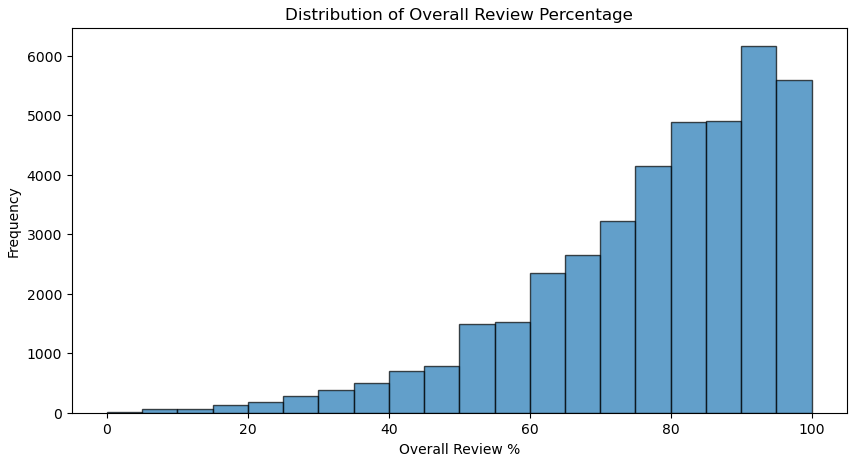
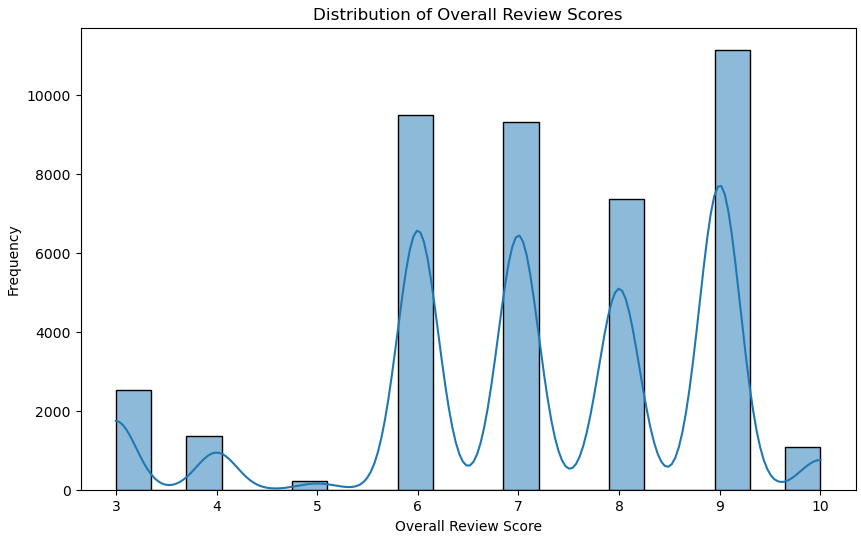
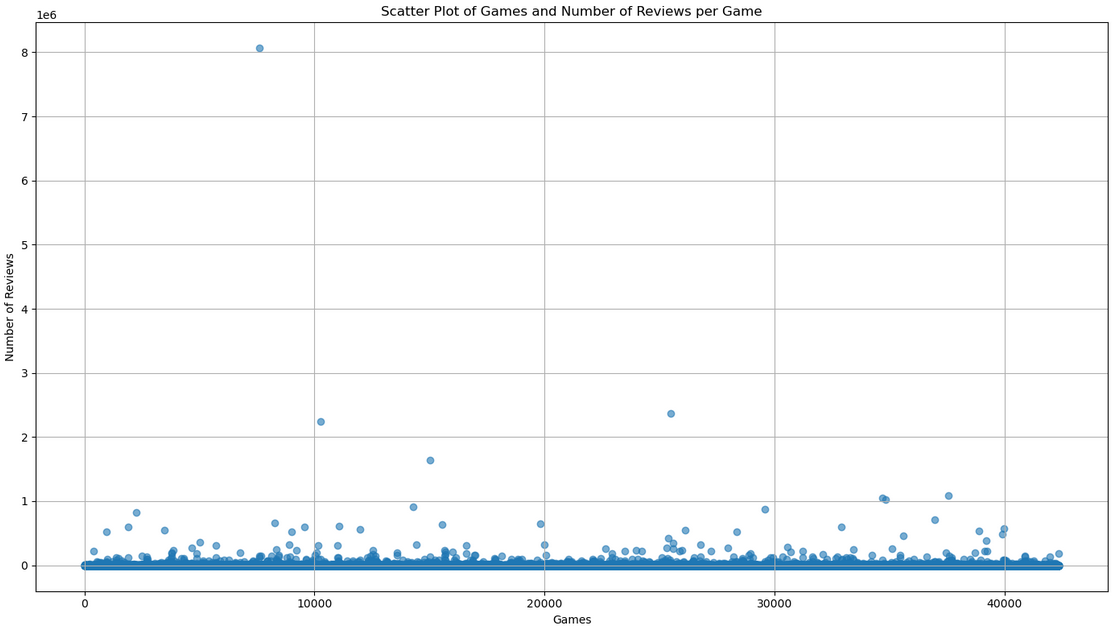
Feature engineering involves creating new features to improve model performance. I focus on transforming the 'categories' and 'genres' columns into binary columns for each category and genre. This transformation allows the model to better understand the presence or absence of specific game features. I also combine smaller or similar categories into broader ones to reduce dimensionality and improve model interpretability.
<class 'pandas.core.frame.DataFrame'> RangeIndex: 42497 entries, 0 to 42496 Data columns (total 23 columns): # Column Non-Null Count Dtype --- ------ -------------- ----- 0 title 42497 non-null object 1 win_support 42497 non-null bool 2 mac_support 42497 non-null bool 3 linux_support 42497 non-null bool 4 overall_review 42497 non-null float64 5 overall_review_% 40020 non-null float64 6 overall_review_count 40020 non-null float64 7 Single-player 42497 non-null bool 8 Cross-Platform Multiplayer 42497 non-null bool 9 VR Supported 42497 non-null bool 10 LAN Multiplayer 42497 non-null bool 11 Online Multiplayer 42497 non-null bool 12 Indie 42497 non-null bool 13 Action 42497 non-null bool 14 Adventure 42497 non-null bool 15 Casual 42497 non-null bool 16 Simulation 42497 non-null bool 17 Strategy 42497 non-null bool 18 RPG 42497 non-null bool 19 Free to Play 42497 non-null bool 20 Sports 42497 non-null bool 21 Racing 42497 non-null bool 22 Massively Multiplayer 42497 non-null bool dtypes: bool(19), float64(3), object(1) memory usage: 2.1+ MB
Before training the model, I convert verbose review scores to numerical values and consolidate games with low review scores into a single category, considering any score below 5 negatively received. I also removed games with extremely high review counts to prevent skewed predictions. Finally, I split the dataset into training and testing sets for model validation.
I choose a classification model for this project to predict whether a game will succeed. I use the Multi-Layer Perceptron Classifier (MLPClassifier) from Scikit-learn, an artificial neural network suitable for classification tasks. The model architecture included two hidden layers, with 64 nodes in the first layer and 32 nodes in the second.
After training the model, I evaluate its performance using standard metrics such as accuracy, precision, recall, and F1 score. The results were as follows:
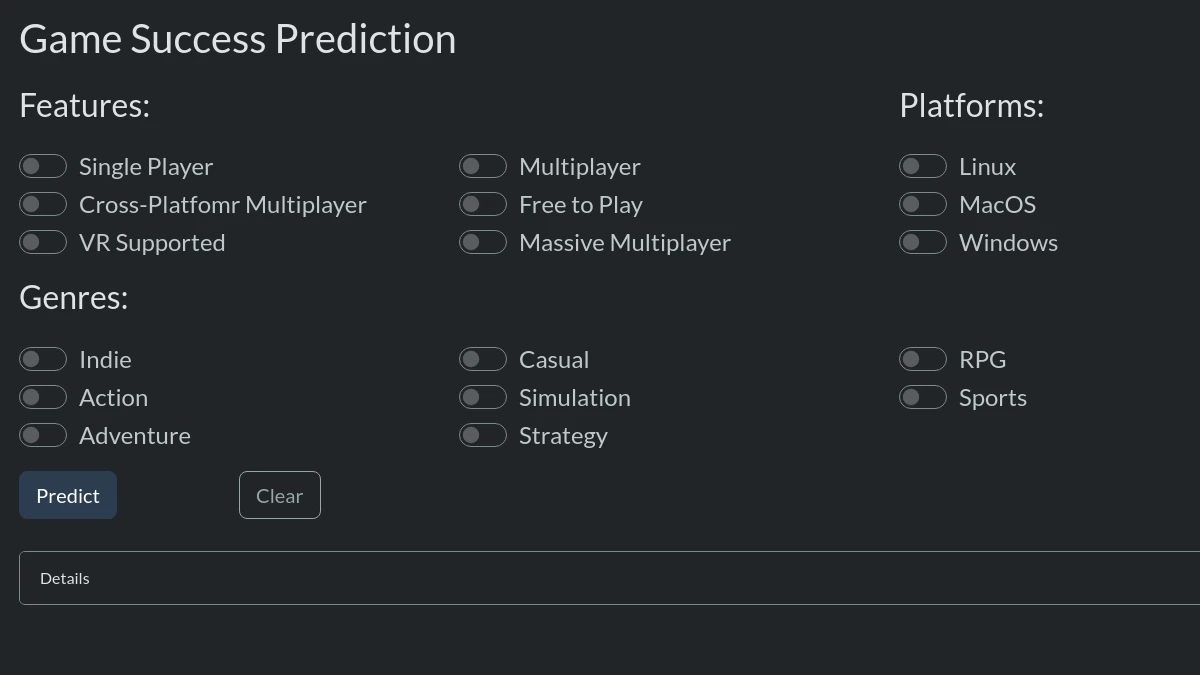
The model is saved as a pickle file and can be loaded and used to make predictions. I deploy the model using Django, a high-level Python web framework, as a back-end API. The application's front-end is built using HTML, CSS, and JavaScript. The user can choose the game's features by toggling the checkboxes and clicking the 'Predict' button to see the prediction. The application is available here.
This project sdemonstrates how machine learning can be applied to predict the success of video games based on their features. By leveraging a diverse dataset of Steam games, we explored the relationships between game characteristics and their potential success, as measured by user reviews and other metrics.
The process involved extensive data cleaning, exploration, feature engineering, and preprocessing to ensure the quality and relevance of the data. Through careful model selection and training, we developed a Multi-Layer Perceptron Classifier that accurately predicted game success. Although there is room for improvement in model performance, the results are promising and provide a solid foundation for further development.
The model could be enhanced in the future by:
Overall, this project provides valuable insights into the factors contributing to a video game's success and demonstrates the potential of machine learning in the gaming industry. The deployed model offers a practical tool for developers and publishers to assess the potential success of their games based on key features, ultimately aiding in better decision-making and strategic planning.
 That Builder Guy
That Builder Guy